Creating a complex project with LLMs
I have been using Gemini for a while and I was up for a challenge of creating a complex project with microservices for testing their capabilities, so I created a scalable scraper.
Introduction
Some years ago I worked at a company that had a scraper. The architecture was already in place and I had to fix scalability issues, release it to AWS, and create a user interface.
The other day I thought about using LLMs to replicate the project and talk about the experience. So I have been working with Gemini, and I have I created a scraper (Isidorus Web Scraper) that could run in AWS with minimal configuration and that would perform well.
The Isidorus project
While not being the focus of this post, let me give you some context about the project.
Isidorus is a web scraper that extracts the images, explains them, summarizes the content, and index web pages in an OpenSearch database. All the communication is based on SQS queues, and the work is done by Python (Page summarizer, image explainer, and deletion) and golang workers (scraper, image extractor, open search indexer, and database writer).
The main aim of this project is to serve as a showcase for a real use-case built by heavily leveraging LLMs.
The project is not deployed to any cloud, but it runs locally by making use of LocalStack.
What do you need?
Knowing the problem well
I tend to start defining the aim at the beginning. As any aim, it is a bit vague, but in this case, after I told the aim (to build a web scraper), I started describing to the LLM the architecture that I had on my mind.
Having worked on the same problem years ago gave me some experience about how is this system. So I just described what were the parts of the system and how would I expected it to behave.
I could not have done this if I did not know the problem well. I would have need to do a discovery process (maybe using this LLM), to learn about the different system designs for a web crawler. I know that the one I chose is not the best, nor the most efficient, but it is easy to understand and this was an experiment, not a real project.
Knowing the tools well
I have some experience with the Python programming language1, less with golang, but I know enough to understand it and know what it does. At the end of the day is just another syntax, with a lot of cool features, but mostly the same.
I dabbled a lot with Docker in my previous job, so I am equipped to deal with the issues that can arise. To be fair, Docker is not a tool that worries me much, as it is well-defined and works pretty well2.
I had just discovered LocalStack several weeks ago, played around enough to know that it can simulate the most popular AWS services, so I could run the infrastructure locally. I do not want to pay AWS for a showcase, and I am not worried about performance for a proof of concept. I just want a way to develop and run a non-trivial project.
How to do it? i.e. the virtuous cycle
I work in cycles similar to what the TDD developers do. But instead of creating the test first, I create some draft code that has the functionality, and then I create the tests that ensure the functionality. When I say tests, I mean unit tests and end to end tests.
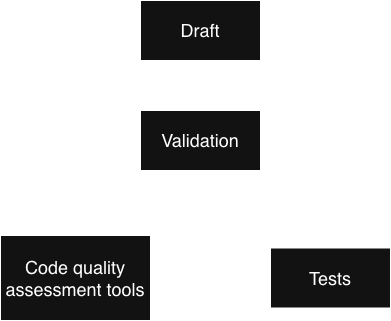
1. Drafting the code
I ask the AI agent to create the minimum piece of code that does what I want. I do not care about good practices, community guidelines, patterns, etc. I just want a piece of code that does a thing.
2. Fixing the functionality
Here, I create a scaffolding that will support subsequent improvements on the drafted code.
Unit tests
The unit tests describe the dependencies and relationship with the tested module and the others. They are a good way to ensure that the contract between the tested module and its dependencies is stable.
I tend to follow the London school of testing, where I check the calls done by the dependencies.
In case of a refactor, usually they need to be changed.
E2E tests
Sometimes called (system) integration tests, they are tests where our project is put together with mocked services that simulate its dependencies.
The E2E tests ensure the functionality itself. They act as black-box tests where the inner workings are ignored, and only the interface and the results are taking in account.
3. Improvement
As I said earlier, each improvement needs to pass the E2E tests. So, we can use those as a way of making the LLM get feedback automatically. In my case, the Agent ended up reading the docker logs and querying the database to check what was the actual outcome of the code vs the expected one.
I have applied two types of improvements during the development of this project:
Directed Improvement
Now, I start applying all good practices I can think of. Every time I ask the AI agent to improve the code, I know that the E2E tests need to run successfully, and the unit tests need to (usually) be changed.
I also ask the LLM to record this practice in the context (in my case, the GEMINI.md file). Sometimes I have tried to use pre-defined contexts, but in the case of this project, I did not do it. I just started applying good practices/guidelines/architecture as long as I was seeing the project grow.
The important part of this improvement is to keep the same functionality. So when we created the E2E tests, we needed to be aware that the responsibility of the code working fine is going to be on them.
Improvement discovery
Another thing I do is to ask the LLM about what best practices from the community can be applied. Then, an interesting conversation between me and the LLM starts. Maybe I know the best practices, but if I am missing anything? Maybe I do not remember or have a bad day.
So I rely on the community approved patterns. Note that I do not ask the LLM for their opinion, but I ask the LLM to bring up the opinions of the software development community for that particular technology.
Now, I need to value if the improvement needs to be applied or not. In case that I decide to apply the practice I immediately update the context file too.
3. Validation
Every change needs to be validated. Not doing that is dangerous, as the LLM can inadvertently adding defects.
Above all, I have suffered from context rot, and have found the AI agent to be modifying files that were not related at all to my prompt. The Agent was trying to stablish some kind of connections among concepts in a convoluted (no pun intended) and erroneous way.
To solve this context rot issue I found myself restarting the Agent. Is this the best solution? I do not think so, but as my GEMINI.md file grew, I found myself more confident in the context quality of the project, so I did not need to be so descriptive in my prompts.
Code quality tools, linting, and other formatting tools
I am one of those people that thing that external order implies internal order. In this case, I always like to apply linter and code quality tools, to have another feedback for the LLM.
It is good to keep order, but the community sets guideline in place for a reason. Thousands of developers have agreed to do things in a way, why do not we do it like that?
Apart from that, most of the guidelines are actually good for the codebase, so it would be counter-productive to just ignore those guidelines and do whatever I decide.
But the most important reason for doing this is that we are following the code patterns the LLM has learned on. Most of the people follow the community guidelines (e.g. PEP8 in Python), by following us too we ease the understanding of the code by the LLM. So we are improving the generational process (this is a hypothesis, but it seems logical).
Knowing when to stop
One of the most important lessons I learned while doing this project is to know your limitations, i.e. know when to stop. Let me tell you the full story.
While I was developing the workers, I was doing them in Python. I thought that it did not matter much as they were limited by I/O (reading/writing to the database) and I am skilled in the language.
However, after a series of refactorings, that was not true anymore. Not all the jobs were reading the database, so I started considering alternatives. I started thinking about other programming language that was faster, with less memory footprint, and that was more performant. I decided to use golang.
The last time I touched golang was to add a command to a CLI this past year. I used ChatGPT, and a lot of code copy-pasted from the same project (most of the code was boilerplate). Anyway, there was a point where I was presented with improvements in the golang code that I could not understand well. So I did not applied the change. Maybe the code I have left in the project is not the most efficient, and that could be improved, but I think most engineers can understand it. The proposal the LLM showed to me was not obvious, for sure it was better but I am more concerned in the maintainability than in being 10% more performant.
What I did not use?
Roles
I did not asked the LLM to play a role, nor deal with the problem as if they were an engineer/developer/project manager/etc. I think that Antigravity + Gemini in Plan mode and all edit permissions on is a good way to work. I do not know.
Several AI agents
Maybe my project would have been built better or faster if I would have used a network of agents working together. Sometimes I think that this virtuous cycle could have been completely automated3.
If I achieve something on that direction I will write it here.
Keeping the same model
To be fair, when my quota ran out I just selected another model and kept working. Should I have waited until my quota was renewed? I do not know. I have not detected issues when using Gemini 3 Flash vs Gemini 3 Pro (for example). Maybe I needed to be more inquisitive in my orders but… who cares if the result was improved again and again until it reached a good quality?4
Conclusion
In this post I have explained how I have created a complex project (a web scraper) by leveraging the LLM technologies, but running LLM agents in a feedback loop with me and other tools.
I also explain how I stopped myself when I could not go faster more without understanding de decisions that the LLM was taking, and hence, making mistakes.
-
in case you are interested in checking out some of my most interesting Python projects, take a look at gelidum, otelize, mypy-raise, and mypy-pure. If you work with Django, take a look at Django-async-include, and Django-ws-include. ↩︎
-
well some years ago I hit a roadblock with some different implementation details between the Linux and MacOS docker versions, but apart from that, my experience with docker is smooth. ↩︎
-
there are some LLM agent architectures that seem to be working well for some developers, creating this develop-review cycle almost autonomously. Claude Code has enabled a preview of this feature. ↩︎
-
as of February 2026, having a good context is better than running the latest LLM model. ↩︎